NGLA: Next Generation Log Analytics
Please note the details presented here are already covered in USPTO
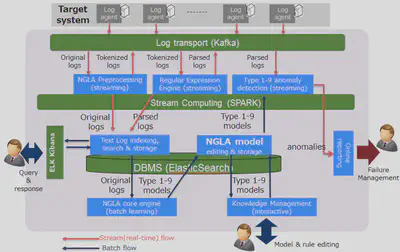
Today, most sophisticated technologies like IoT, Big Data, Cloud, data center consolidation, etc., demand smarter IT infrastructure and operations. They continuously generate lots of logs to report their operational activities. Efficient operation and maintenance of the infrastructure require many of the least glamorous applications, such as troubleshooting, debugging, monitoring, security breaching in real-time. Logs spot the fundamental information for them and are useful to diagnose the root cause of a complex problem. Because of the high volumes, velocities, and varieties of log data, it is an overwhelming task for humans to analyze these logs without a real-time scalable log analysis solution. We find that existing log analysis tools and solutions do not offer enough automation to ease humans burden. To solve this issue we have designed “Next Generation Log Analysis”(NGLA) a streaming log analytic framework.
We have implemented NGLA using a scalable distributed streaming framework, a message broker, and unsupervised machine learning based techniques. First in a training phase we learn the log patterns, and leverage these to generate models for causality, timeseries feature relationships, predictive analysis, and semantic analysis. These models are then used in real-time analytic framework(Spark Streaming) to scale out and analyze/detect anomalies in a large volume of logs. Offline querying is currently supported using ElasticSearch.
Pattern Recognition (Team Member)
(details to be added) NGLA uses novel log pattern extraction using training logs, and generating regular expressions. The process is broadly the following
- Tokenization: All logs are tokenized using space delimiters, tokenization is done at different levels. At the most granular we keep all logs as is, and form precise patterns. At a higher level strings are converted to words (\W), number are converted to decimals (\d) and so onwards.
- Preprocessing: Special tokens like IP addresses, dates etc. are converted to symbols
- Fast Clustering: At every level fast clustering is done using hashing
- These patterns are then used to tokenize logs according to patterns learnt.
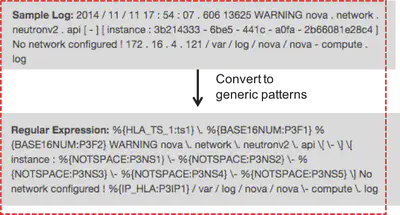
The figure above demonstrates the tokens created from a log based on the patterns learnt.
Service Oriented Architecture for Spark Streaming Anomaly Detection (Led and Develop)
Our high level goal was to create a service oriented architecture which could take model management and anomaly detection task requests via a Kafka control channel, and consumes all input through a dedicated Kafka data channel.
As a part of this effort we have made modifications to the Spark Streaming platform to generate a generic solution with two additional functionalities: rebroadcasting and efficient state handling mechanism. One of the key novelties in the system design was a plug and play framework which allowed new anomaly algorithms to be easily added. In addition, we also solved the challenge of rebroadcasting “broadcast variables” in a streaming context, by making a small change in the spark internal code.
In our implementation of the NGLA framework we found that several common tasks are repeated across different anomaly detection algorithms. Examples of these are: model loading, model deletion, publishing and saving anomaly results, ingesting data streams, maintaining in memory states, dynamically updating models on change from training phase (presented later). In order to abstract out these common tasks, we created an abstraction called violation checker. We broadly divided all anomaly detection techniques in three broad categories:
- Stateless: These are anomaly detection techniques, which are completely independent of any other log
- Stateful: These are causal in nature and require a state for detection
- TimeSeries: These are analysis that work on Timeseries data
Our abstraction called “Violation Checker” is an interface which implements common tasks and allows for streaming data management. The “violation checker” has the following functionalities:
Service level interface:
Receive and manage requests for anomaly detection for new incoming data or updating the model of existing testing data streamsRead and Broadcast Model (Abstraction and Service Level):
This abstraction allows us to read model from ElasticSearch, and to broadcast the read model. Each anomaly detection algorithm implement its own model parsing from a JSON Object as an input and creating a model object, which is broadcast by the interface.Delete Model (Abstraction and Service Level):
Delete existing model streams identified by the id for the request.Update Model (Service Level)
Update the broadcast model, by reading it from the model database again.Execute Stream (Abstraction)
An abstraction which is implemented for every anomaly detection algorithm. This interface gets the kafka data stream as an inputPublish Anomalies
State management
TimeSeries Generation
All parsed logs can be tokenized, parsed and associated with specific patterns based on the patterns learnt during the training phase. The timeseries based anomaly detection can convert incoming parsed log streams into timeseries with the following format <Timeslot>, <Pattern>, <Frequency> Here the timeslot is the ending timestamp of each time bucket (for instance 10 second bucket, would have a timeslot at 10 sec, 20 sec, 30 sec etc.), and the frequency is the number of logs of the particular pattern received in that timeslot.TimeSeries Alignment
Multi-source timeseries can be from multiple different non-synchronized sources, this means that the timeseries received in a single micro-batch may not be from the same timeslot in the source. We do a best-effort aligment by waiting for the next timeslot from all sources before proceeding with a combined timeseries analysis. Hence if a micro-batch has received the following timeslots Source 1: <Timeslot 1>, <Timeslot 2>, <Timeslot 3>, <Timeslot 4> Source 2: <Timeslot 1>, <Timeslot 2>, <Timeslot 3> Aligned Output: <Timeslot 1 <Source 1, Source 2>>, <Timeslot 2 <Source 1, Source 2>> Assuming a sorted input. The aligned source will only have slots 1 and 2 as we can only be sure that the we have received complete information regarding the first two slots
Dynamic Model Update (Led and Develop)
One of the key challenges we faced when designing the system was dynamic model update. The models learnt during our training phase are kept in “broadcast variables” inside spark. These variables are immutable and are created when the spark context is initiated for streaming. While re-broadcast is trivial through the spark api for regular batch based processing. In our streaming architecture this is a big challenge as once the streaming context has been started it is impossible to modify it.
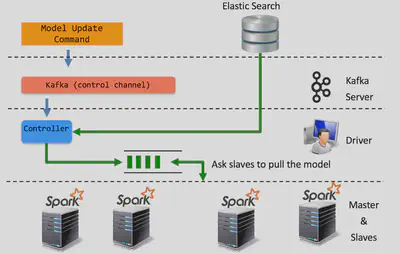
We introduce two concepts to support model update in Spark
A new abstraction called ControlCommandHandler class which is called between every subsequent micro-batch
Model Update Controller which implements the ControlCommandHandler and creates a thread which listens on incoming Kafka requests for model update
A re-broadcast mechanism, which allows overwriting existing broadcast model entries by introducing broadcast with a specific identifier
Scroll down for snippets of the code change
HeartBeat Implementation (Led and Develop)
Another challenge we faced for stateful anomaly detection was periodically checking if certain states are already stale and are anomalous because of time elapsed. While system time could potentially be used we wanted to use time from the data source since data could be sent at different intervals (could be collated, not in real time or in a different time zone).
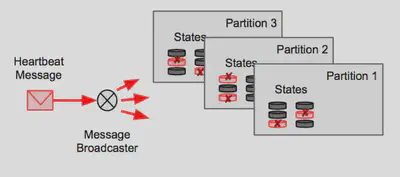
For this we developed an external heartbeat protocol which sends a timestamp from the source at a fixed interval. While normally the timestamp would be enough but states in spark streaming can only be accessed using Keys, which are data dependent, i.e. depends on the data you have processed in the past. States are also distributed which means that each partition can have only some states while other partitions have other states dependent on the key.
Hence, we needed a heartbeat process which would
- Send the message to all partitions - this was implemented by having a custom partitioner which ensured creating a copy of the data for all partitions
- Modify spark so that “parent state map”, can be accessed from the spark streaming application
Stateful Anomaly Detection (Led and Develop)
Enterprise system have a lot of business processes with complex interdependent operational workflows. Each of them has a finite set of event or transaction that contains a finite action sequence. Malfunctioning of any of them may cause a total system failure. Log sequence anomaly detector detects the malfunctioning event or transaction by analyzing the sequence of logs generated by its action sequence. It builds a model with profiling normal log sequences in trans- actions during the learning phase and uses them to identify abnormal log sequences and detects them as anomalies.
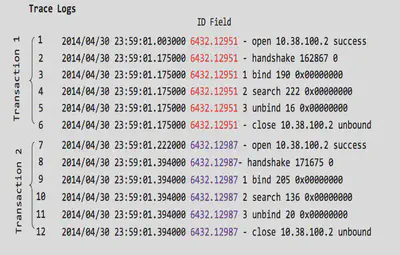
Above are some sample logs with two sample transactions. These are tokenized into patterns, which are then used in our log sequence based anomaly detection algorithm.

These are the patterns generated for the above sample logs.

Source Code Snippets
1. The following are source code snippets for support of Dynamic Model Update in Spark Streaming
Source: NGLA Model Update Manager
public class ModelUpdateController extends ControlCommandHandler implements Runnable {
.....
/**
* function run between micro-batches
**/
@Override<br>
public void interJobNotification() {
synchronized (commandsQueue) {
for(ControlMessage cm : commandsQueue){
printout("The following Control Message " cm.toString());
if(cm.checkForTermination()) {
printout("Terminating Spark Job Now!");
publishAcknowledgment(cm,this.getClass().getName());
javacontext.cancelAllJobs();
ssc.sc().stop();
ssc.stop();
javacontext.close();
javacontext.stop();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
printout(e.toString());
}
printout("Exiting the application!");
System.exit(1);
}
reBroadcastVariables(javacontext , cm);
}
commandsQueue.clear();
}
}
}
Source: oss/spark-1.6.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scala
/**
* @ NGLA
* This abstract class's fucntion interJob Notification will be involed between the micro batches.
* */
abstract class ControlCommandHandler{
//interjob notification is defined within the model update controller
def interJobNotification()
}
/**
* @ NGLA
* Following variable holds the controller lock object
* This handler is used to pause the initialization of the new jobs so that the broadcast variables can be flushed out and rebroadcasted
**/
var commandhandler_ : ControlCommandHandler = null
def getControlChannelHandler() : ControlCommandHandler = commandhandler_
//this is called in SparkDriver
def setControlChannelHandler(h:ControlCommandHandler) = {commandhandler_ = h}
def notifyInterJobStatus(): Unit ={
if(commandhandler_ != null){
commandhandler_.interJobNotification()
}else{
logWarning("Inter job handler is not set")
}
}
spark-1.6.1/core/src/main/scala/org/apache/spark/SparkContext.scala
def broadcast[T: ClassTag](value: T, id:Long): Broadcast[T] = {
assertNotStopped()
if (classOf[RDD[_]].isAssignableFrom(classTag[T].runtimeClass)) {
// This is a warning instead of an exception in order to avoid breaking user programs that
// might have created RDD broadcast variables but not used them:
logWarning("Can not directly broadcast RDDs; instead, call collect() and "
"broadcast the result (see SPARK-5063)")
}
val bc = env.broadcastManager.newBroadcast[T](value, isLocal , id)
val callSite = getCallSite
logInfo("Created broadcast " bc.id " from " callSite.shortForm)
bc
}
spark-1.6.1/core/src/main/scala/org/apache/spark/broadcast/BroadcastManager.scala
def newBroadcast[T: ClassTag](value_ : T, isLocal: Boolean , id:Long): Broadcast[T] = {
broadcastFactory.newBroadcast[T](value_, isLocal, id)
}
2. The following are source code snippets for HeartBeat in Spark Streaming
Source: org.necla.ngla.loganalyzer.stateful.Type9.Type9ViolationChecker
if(IDs[0].contains(ValidationCheckerWithStateUtil.getEOFStateLogID())) {
if (broadcastModel.value().containsKey(IDs[1])) {
LogMessage next = logMessages.get().iterator().next();
//Iterate through all the states in a partition
scala.collection.Iterator<Tuple3<String, Object, Object>> itr_state = state.parentStateMap().<String, Object>getTypedStateMap().getAll().toIterator();
if(debugFlagType9) {
printout(eventLogID + " Before Removing");
printStateMap(state, eventLogID);
}
ArrayList<String> keysMatching = new ArrayList<String>();
List<String> listEOF = new ArrayList<String>();
//go through all states
while (itr_state.hasNext()) {
Tuple3<String, Object, Object> stateObject = itr_state.next();
if (stateObject != null) {
Type9StateManager statePatternLogForType9 = (Type9StateManager) stateObject._2();
if (stateObject._1().contains(IDs[1])) {
keysMatching.add(stateObject._1());
//Type 9 EOF detection code
if(statePatternLogForType9!=null) {
String idValue = stateObject._1().split(DELIMITER)[1];
HashMap<Integer, Automata> integerAutomataHashMap = seqAutomataBroadcastVar.value().get(IDs[1]);
List<String> tempList = statePatternLogForType9.findMissingEOFAnomalies(IDs[1], next.getESTimeStamp(), integerAutomataHashMap, idValue);
if (!tempList.isEmpty()) {
listEOF = tempList;
break;
}
}
}
}
}